机器学习_scikit_learn演示。
1.机器学习的分类
1.1有监督学习 :特征(A)和标签(vector_b)之间建模
分类:预测离散标签
特征 1、特征 2……特征 n → 垃圾邮件关键词与短语出现的频次归一化向量(“Viagra” “Nigerian prince”等)。
标签 →“垃圾邮件”或“普通邮件”。
- 高斯朴素贝叶斯分类
- 支持向量机
- 随机森林分类
回归:预测连续标签
特征 1、特征 2……特征 n → 具有若干波长或颜色的星系的亮度。
标签 → 星系的距离或红移(redshift)。
1.2无监督学习:不带任何标签
聚类:为无标签数据添加标签 ——数据被聚类算法自动分成若干离散的组别。
- k-means :簇中的每个 点到该中心的总距离最短
- 高斯混合模型
- 谱聚类
降维:推断无标签数据的结构
- 主成分分析
- Isomap 算法
- 局部线性嵌入算法
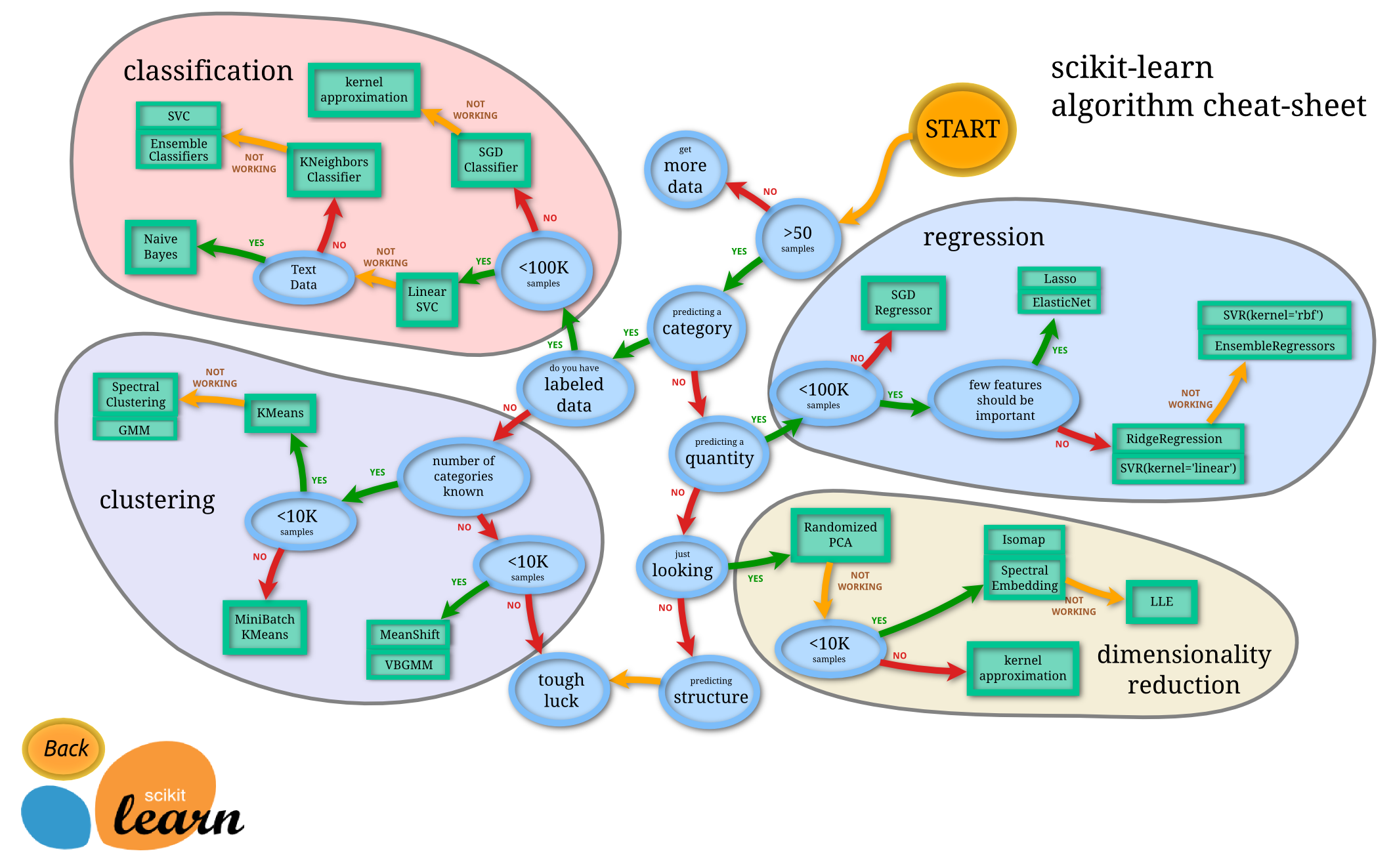
步骤:
- 样本数量少于50个,继续获取更多数据
- 多于50个样本数据后,若预测变量属于标签类数据进入有监督学习;若无标签进入无监督学习
- 有监督学习,若预测变量是离散型,分类问题;若预测变量是连续型,回归问题
- 无监督学习:不带任何标签。为无标签数据添加标签,聚类;推断无标签数据的结构,降维
2.Scikit-Learn回归模型演示
- 从 Scikit-Learn 中导入评估器类。
from sklearn.linear_model import LinearRegression
- 模型超参数(hyperparameter)。
model = LinearRegression(fit_intercept=True)
model
- 获取特征矩阵和目标数组。
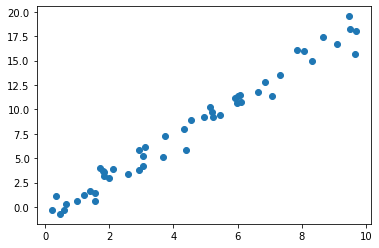
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(42)
x = 10 * rng.rand(50)
y = 2 * x - 1 + rng.randn(50)
plt.scatter(x, y);
X = x[:, np.newaxis]
X.shape
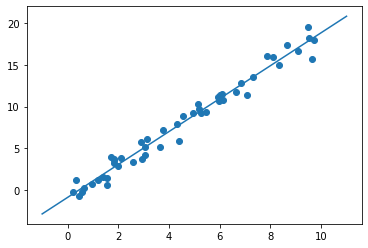
- 调用模型实例的 fit() 方法对数据进行拟合。
model.fit(X, y)
model.coef_
model.intercept_
- 对新数据应用模型:
# 将这些x值转换成[n_samples, n_features]的特征矩阵
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
# 把原始数据和拟合结果可视化出来
plt.scatter(x, y)
plt.plot(xfit, yfit)
6.监督学习模型,predict() 预测新数据的标签; 无监督学习模型,使用 transform() 或 predict() 转换或推断数据的性质。